Your SBOM is only as useful as it is accurate, and the method you use for Software Bill of Materials (SBOM) generation determines the level of accuracy you will receive.
SBOM generation method determines whether an SBOM captures what developers declared, what scanners can detect, or what actually gets compiled into your software. For example, a source code scan might show a clean dependency tree while your actual build incorporates dozens of undeclared libraries. Those invisible components carry vulnerabilities that won’t appear in any scan results.
This guide breaks down how source code, binary, and build-time SBOM generation work, where each method falls short, and which approach delivers the accuracy that embedded software teams require.
How Binary-Based SBOM Generation Works: The Pre-Packaged View
Binary-based SBOMs are generated by analyzing compiled software, focusing on the final product rather than the source code or build process. It examines compiled executables or firmware images after a build completes to identify components and dependencies.
Strengths and limitations of binary SBOMs
Binary-based SBOM generation does not require access to source code, making it valuable for evaluating third-party software or legacy systems where the original source code isn’t available. This includes commercial off-the-shelf software, acquired codebases, and firmware from suppliers that don’t share source code.
However, relying solely on binary analysis often results in SBOMs that lack critical details, most notably the presence of statically linked libraries. Static linking—where libraries get compiled directly into the executable—merges component code into a single file, obscuring boundaries between libraries. Version detection relies on heuristics that don’t always work correctly.
Some auxiliary data is also lost during compilation, making it difficult to trace the origin and history of certain components due to limited provenance information.
The result is higher false positive and false negative rates compared to other methods. A binary scanner might identify a component that was compiled out, or miss a library whose signatures were altered during optimization. For embedded systems where accuracy matters for long-term vulnerability tracking, this uncertainty creates challenges.
Key takeaway: Binary-based SBOMs provide a practical solution for managing legacy systems or third-party components. However, they typically lack the depth and accuracy of SBOMs generated from source code or during the build process, often resulting in less detail and a higher likelihood of false positives.
How Source Code SBOM Generation Works: A Static View with Broad Coverage
Source code-based SBOMs are generated by analyzing a software’s source tree for a specific target, offering a view of the components involved in the development process. Tools parse manifest files—package.json for JavaScript, requirements.txt for Python, pom.xml for Java, or CMakeLists.txt for C++—to identify declared dependencies. This method has several notable advantages.
Strengths and limitations of source code SBOMs
Source code analysis provides a thorough inventory of all potential components that could be included in the software. It also offers direct access to valuable metadata, such as licensing and copyright information, which is critical for compliance and legal requirements. Additionally, analyzing source code is less computationally intensive than its more involved build-time SBOM counterpart, as it involves simpler, less resource-demanding operations.
However, the source code-based approach comes with its own set of challenges. A key issue lies in the complexity of build configurations. Since this method examines the source tree rather than the final software build, it may fail to accurately reflect the configurations used to generate the actual binaries. This misalignment can result in discrepancies between the SBOM and the final product. Conditional compilation further complicates matters, as accounting for different compilation paths in large, complex codebases with multiple configurations can be particularly challenging.
Another limitation is its inability to capture runtime dependencies—external components that are dynamically fetched during the software’s operation. Consequently, source code-based SBOMs often over-report, including components that may not make it into the final binary and creating unnecessary noise. This can lead to false positives, where components that are in the source code are flagged even though they will not be in the final build and so do not present any business risk.
Key takeaway: Source code-based SBOMs provide greater visibility into all components of a codebase, making them valuable for compliance, licensing, and early development analysis. However, they still miss out on providing the complete picture of the final product and have a strong chance of false positives by not accounting for build configurations and runtime dependencies.
How Build-Time SBOM Generation Works: The Complete Picture
Build-time SBOMs are considered the most accurate and efficient method for tracking software components because they are generated during the compilation process, providing a detailed and reliable view of all the components included in the final software build.
Build-time SBOMs execute against the precise components in the build and only contain the relevant libraries and the specific sub-components used in those libraries during the building of the compiled output. Build-time SBOMs can also capture all external or linked resources that are included only at build time.
The precision of build-time SBOMs reduces alert fatigue and saves engineering teams time by minimizing false positives and eliminating the need to investigate reported vulnerabilities on components that will not be in the final build and that do not present a risk to production.
When implementing build-time SBOMs, look for solutions that easily integrate into your CI/CD pipeline and existing development workflows. For them to be useful, they must fit smoothly into automated workflows without adding extra complexity or causing delays. Also consider performance. Build-time SBOMs increase accuracy, but should not come at the cost of slowing down build times significantly.
Key takeaway: Build-time SBOMs offer the most precise and comprehensive tracking of software components, making them essential for strengthening software supply chain security and minimizing false positives. They can also be created for legacy software where the source code is readily available. To maximize their impact, choose solutions that seamlessly integrate into your CI/CD pipeline.
Comparing SBOM Methods for Accuracy and Coverage
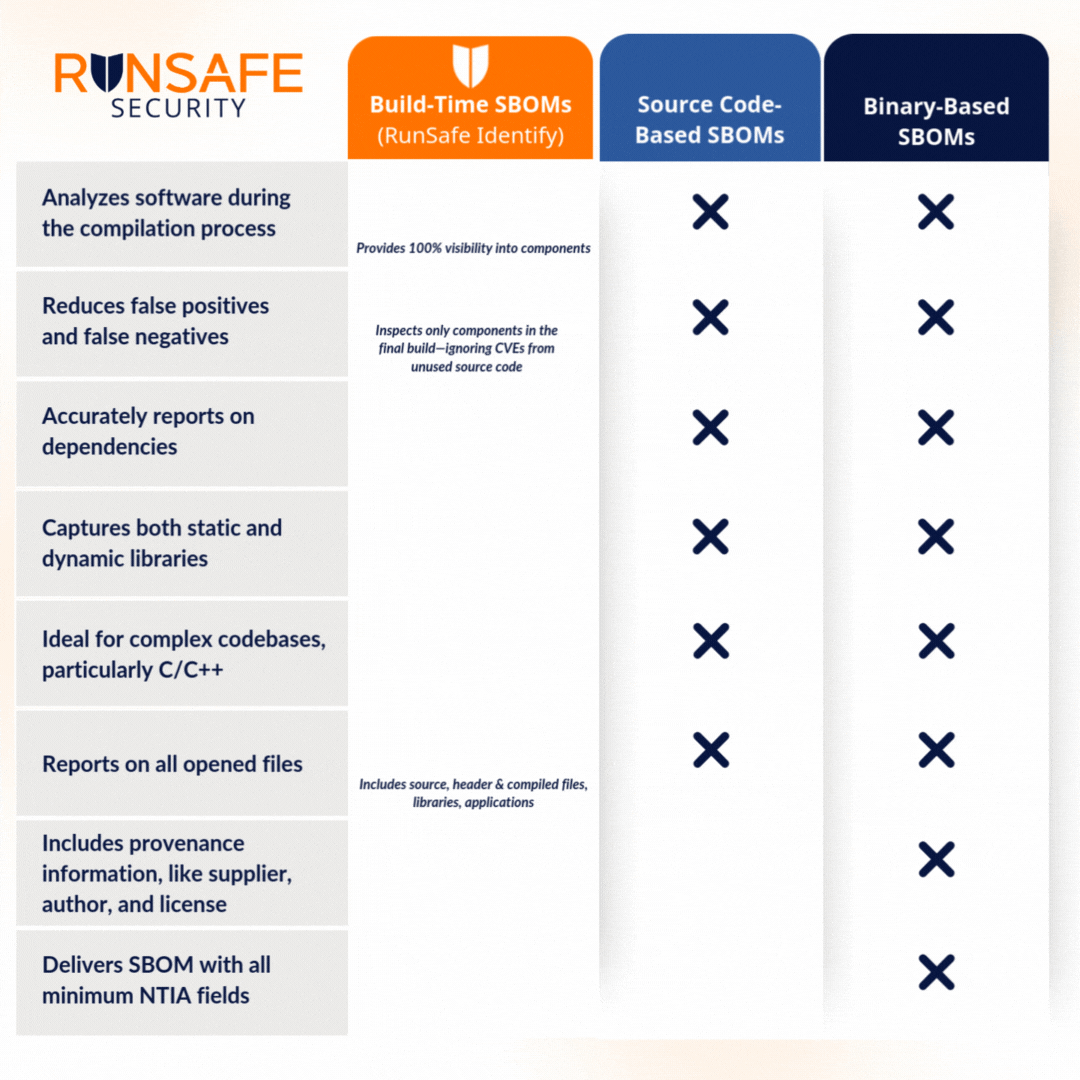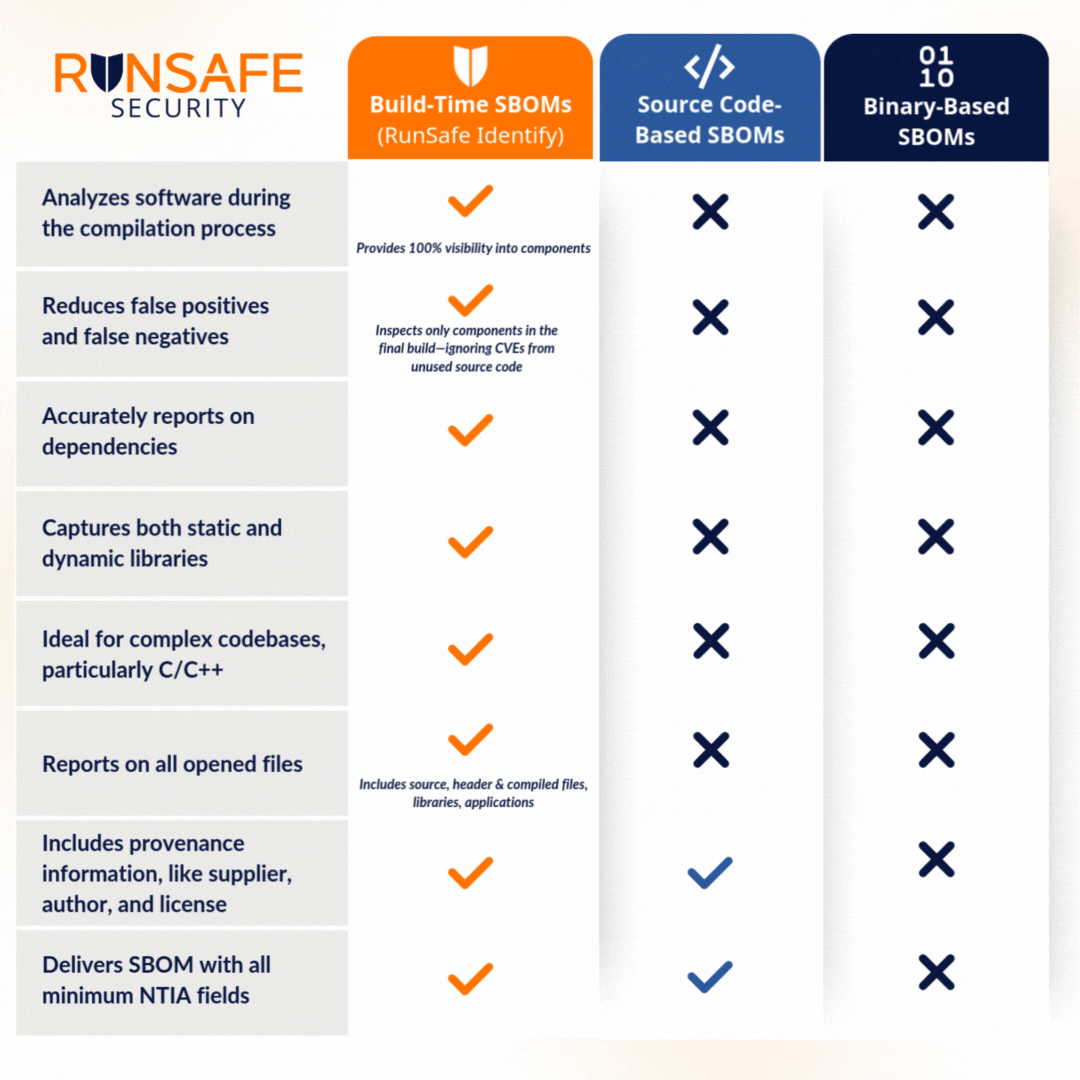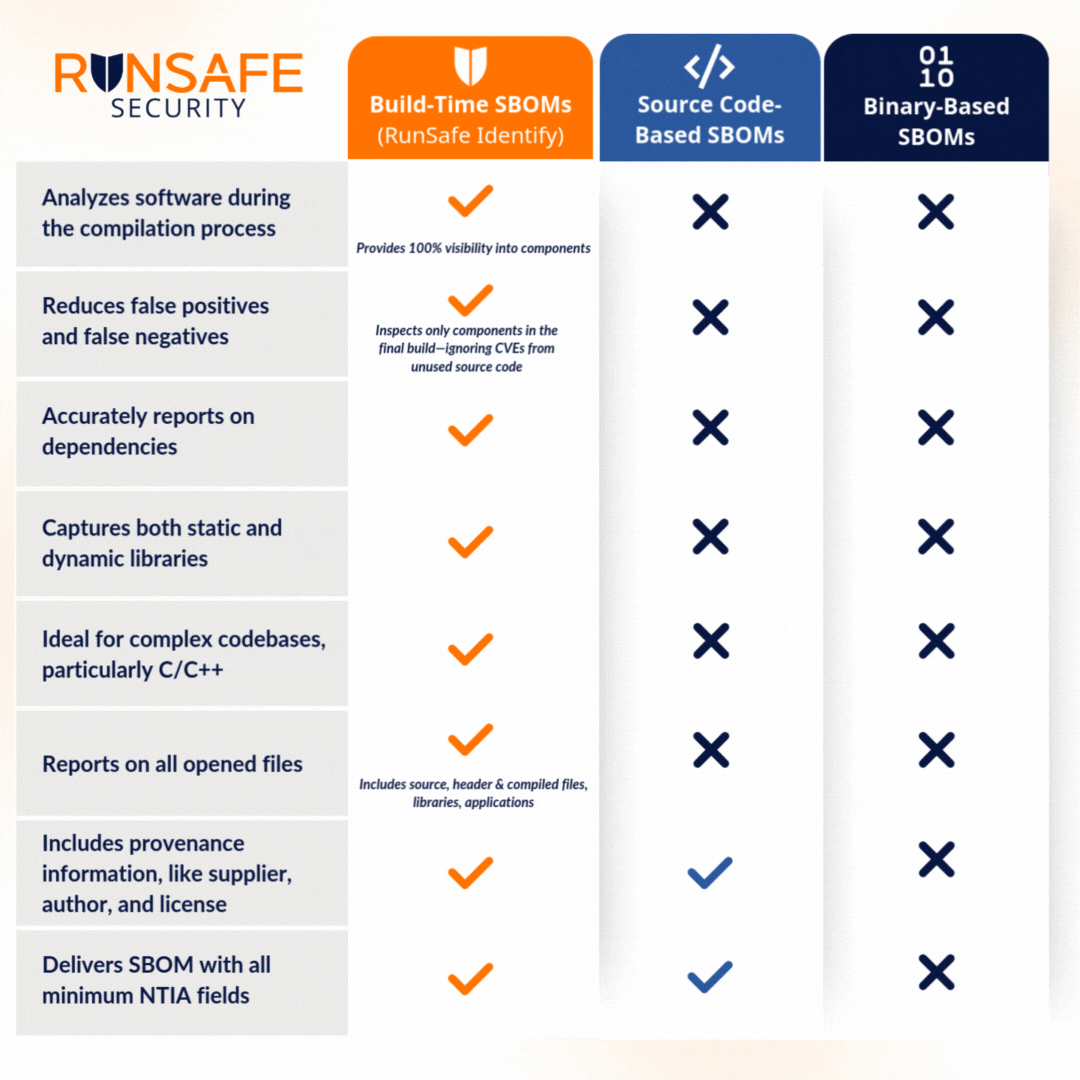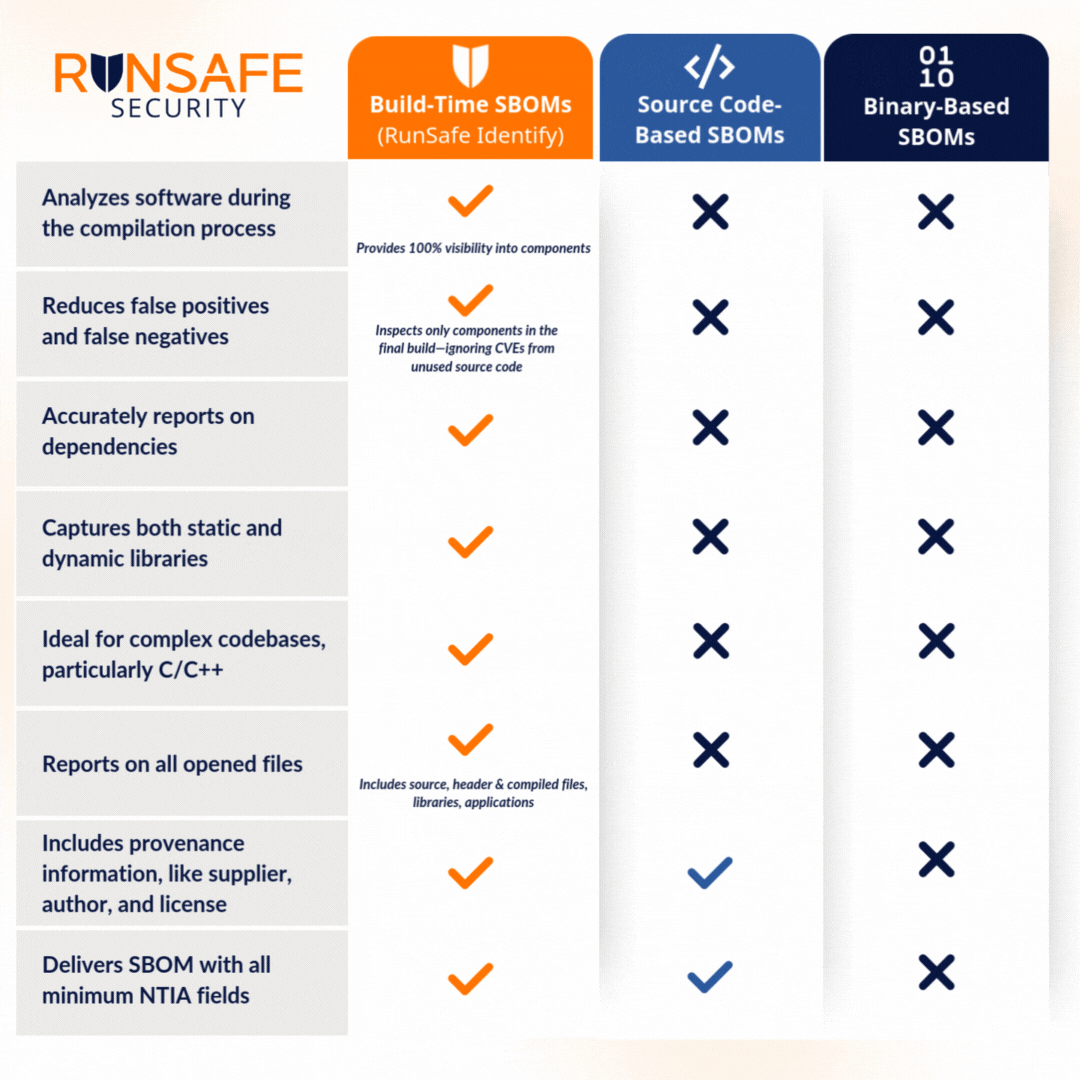
Choosing Your SBOM Generation Tool: Implications for Vulnerability Identification
The type of SBOM you choose can significantly impact your software security efforts. When selecting an SBOM generation tool, consider your specific needs, access to source code, and desired accuracy level.
For most modern development environments, build-time SBOMs will provide the most value and the clearest picture of your software’s actual composition.
A complete and accurate picture of your software’s composition enables more effective vulnerability identification and risk management, allowing you to:
- Maintain strong software supply chain security
- Efficiently identify and address vulnerabilities
- Deliver more secure products
- Meet SBOM regulatory compliance requirements
Build-Time SBOMs Lead the Way in Modern Software Security and Compliance
For teams building embedded software—especially in C/C++—build-time SBOM generation provides the accuracy that other methods cannot match. You get visibility into statically linked libraries, vendored code, and dependencies that never appeared in any manifest file.
That visibility translates directly to better security outcomes: more accurate vulnerability identification, cleaner compliance reporting, and confidence that you understand what’s actually in your software.
Request a consultation to assess your embedded software security and risk reduction opportunities.
FAQs About SBOM Generation Methods
Build-time SBOMs monitor linker activity during compilation, capturing each static library as it gets incorporated into the final binary. This provides visibility that binary analysis cannot reliably achieve after static linking merges component code together.
Can SBOM generators capture third-party components when source code is unavailable?
Binary analysis tools can detect components in pre-built software by scanning for known signatures and strings, though accuracy varies depending on compiler optimizations and linking methods. Build-time generation requires access to the build process, so it cannot analyze externally sourced binaries without rebuilding from source.
Which SBOM generation method meets regulatory compliance requirements?
Most regulations—including FDA guidance and NTIA minimum elements—specify SBOM content requirements rather than mandating a specific generation method. However, accuracy expectations favor methods that capture complete component data, making build-time approaches well-suited for compliance in regulated industries like medical devices and defense.




